EAS提供了ModelScope预置镜像用于快速部署魔搭社区模型,并针对模型分发和镜像拉起做了加速机制。您只需配置几个参数,就可以将社区模型一键快捷的部署到EAS模型在线服务平台。本文为您介绍如何部署ModelScope的社区模型。
背景信息
ModelScope旨在打造下一代开源的模型即服务共享平台,为广泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,使模型应用变得更简单。
对于部署到EAS的ModelScope社区中的模型,可以分为普通Pipeline模型和大语言对话模型,由于加载和使用方式的不同,两种模型的部署和调用方式稍有区别,详情请参见:
部署ModelScope模型服务
支持以下两种部署方式。其中使用场景化方式部署的ModelScope模型服务,仅支持API接口调用方式,不支持WebUI调用方式。
方式一:场景化模型部署
具体操作步骤如下:
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
在模型在线服务(EAS)页面,单击部署服务,在场景化模型部署区域,单击ModelScope模型部署。
在ModelScope模型部署页面,配置以下关键参数,其他参数配置详情,请参见服务部署:控制台。
参数
描述
基本信息
选择模型
在下拉框中选择需要部署的ModelScope模型。
模型版本
选择模型后,系统会自动配置模型版本,您也可以在下拉框中选择其他模型版本。
模型类别
选择模型后,系统会自动配置模型类别。
资源配置
资源配置选择
当选择普通Pipeline模型时,您选择的实例规格的内存不能小于8 GB。
当选择大语言对话模型时,建议选择ml.gu7i.c16m60.1-gu30。
说明目前支持的大语言对话模型列表,请参见步骤一:选择模型。
由于大语言对话模型的体积通常较大,并且对于GPU的要求较高,建议根据实际模型需求选择合适的GPU资源。
针对7B模型,建议选择GU30系列机型。对于更大的模型,可能需要考虑双卡机型或拥有更大显存的机型,请按实际需求选择。
参数配置完成后,单击部署。
方式二:自定义模型部署
具体操作步骤如下:
步骤一:选择模型
在场景化部署模型时,系统自动预设了模型类别和版本信息;而采用自定义部署方式时,您则需手动获取MODEL_ID、TASK和REVISION的值,并保存到本地。
普通模型
以普通Pipeline模型-机器翻译模型为例,进入damo/nlp_csanmt_translation_en2zh模型页面,分别获取MODEL_ID、TASK、REVISION的值并保存到本地。
MODEL_ID:模型ID。
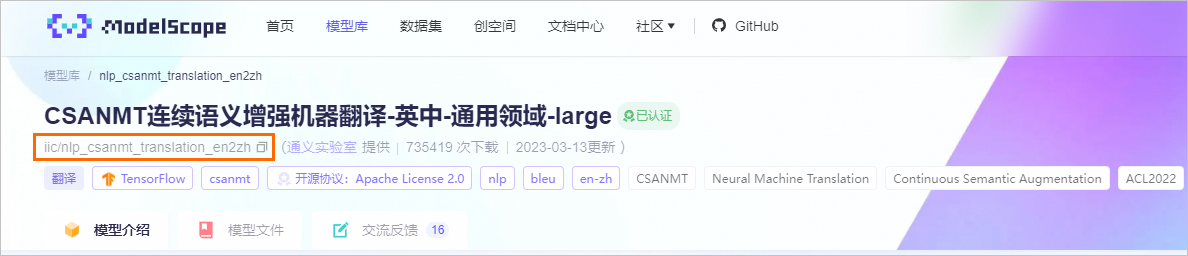
TASK:模型对应的TASK。
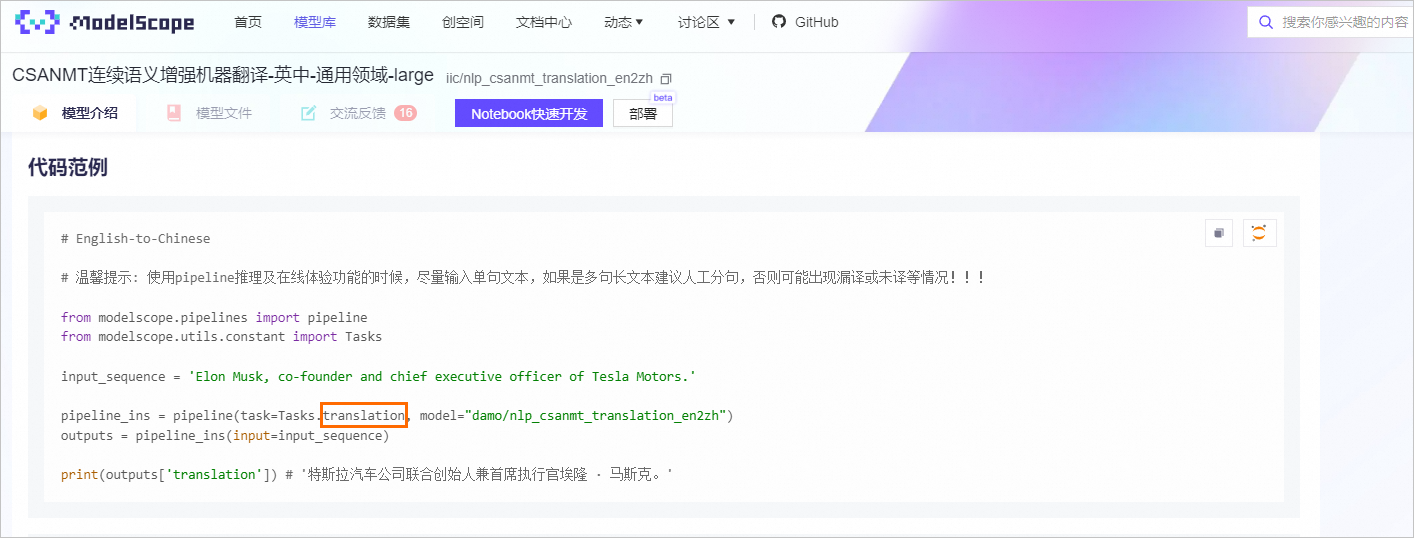
REVISION:模型版本。
说明需要配置为一个确定的模型版本,例如:v1.0.1或v1.0.0,不能配置为master。
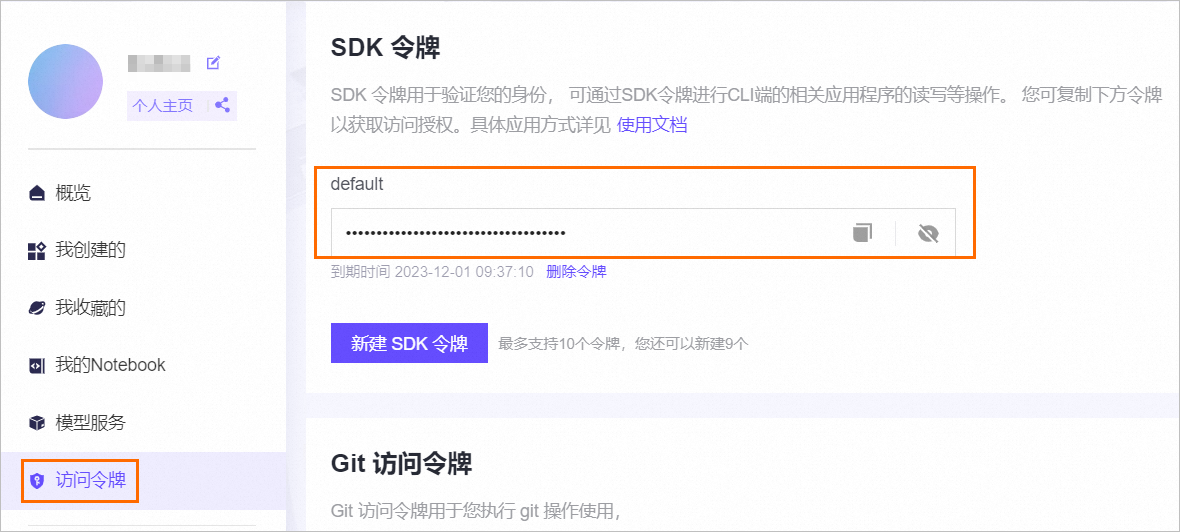
(可选)ACCESS_TOKEN:SDK访问令牌。
当需要部署非公开模型时,需要填写SDK访问令牌以获取模型。请在ModelScope首页的左侧导航栏中,单击访问令牌,在该页面获取SDK令牌。在后续部署服务时,您需要将SDK令牌配置到环境变量中。
大语言对话模型
目前支持的大语言对话模型列表如下:
类型 | MODEL_TYPE | MODEL_ID |
llama系列 | llama |
|
baichuan系列 | baichuan |
|
浦语系列 | internlm |
|
chatglm系列 | glm |
|
qwen系列 | qwen |
|
以ChatGLM系列模型为例,其中:
MODEL_ID:请从上述表格中获取。例如
ZhipuAI/chatglm2-6b。TASK:均为chat。
REVISION:参考普通模型查询方式获取模型版本。例如
v1.0.11。
步骤二:部署模型
登录PAI控制台,在页面上方选择目标地域,并在右侧选择目标工作空间,然后单击进入EAS。
单击部署服务,然后在自定义模型部署区域,单击自定义部署。
在自定义部署页面,配置以下关键参数,其他参数配置详情,请参见服务部署:控制台。
参数
描述
服务名称
参照界面提示自定义配置服务名称。
部署方式
选中开启Web应用。
镜像配置
在官方镜像列表中选择modelscope-inference;镜像版本选择最高版本。
环境变量
单击添加按钮,配置以下参数为步骤一中查询的结果:
普通模型(以机器翻译模型为例):
MODEL_ID:
iic/nlp_csanmt_translation_en2zhTASK:
translationREVISION:
v1.0.1
大语言对话模型(以ChatGLM系列模型为例):
MODEL_ID:
ZhipuAI/chatglm2-6b。TASK:
chat。REVISION:
v1.0.11。
如果部署非公开模型,您需要新增一个环境变量配置访问令牌,如何获取访问令牌,请参见步骤一:选择模型。
变量名:配置为ACCESS_TOKEN。
变量值:配置为已获取的SDK访问令牌。
运行命令
配置镜像后,系统会自动配置运行命令,您无需修改配置。
部署资源
普通Pipeline模型:您选择的实例规格的内存不能小于8 GB。
大语言对话模型:建议选择ml.gu7i.c16m60.1-gu30。
说明目前支持的大语言对话模型列表,请参见步骤一:选择模型。
由于大语言模型的体积通常较大,并且对于GPU的要求较高,建议根据实际模型需求选择合适的GPU资源。
针对7B模型,建议选择GU30系列机型。对于更大的模型,可能需要考虑双卡机型或拥有更大显存的机型,请按实际需求选择。
单击部署。当服务状态变为运行中时,表明服务已部署成功。
调用服务
使用场景化方式部署的ModelScope模型服务仅支持API接口调用方式。
调用普通Pipeline模型服务
以机器翻译模型为例:
启动WebUI调用模型服务
服务部署成功后,单击服务方式列下的查看Web应用。
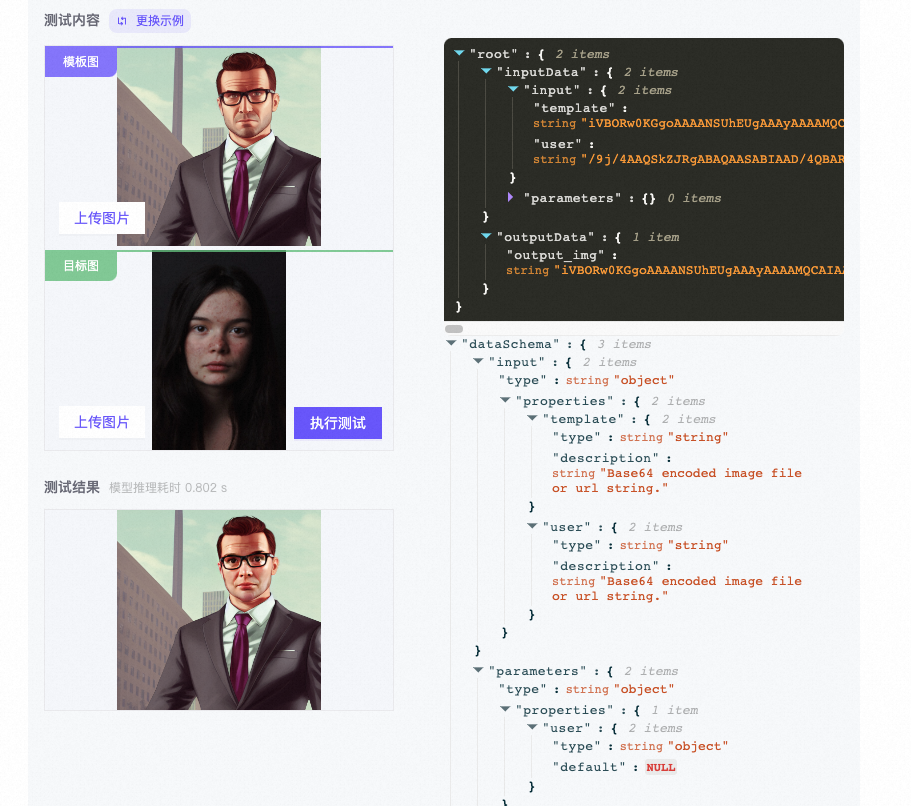
在WebUI页面左侧测试内容文本框中输入请求数据,单击执行测试,在测试结果文本框中返回结果。
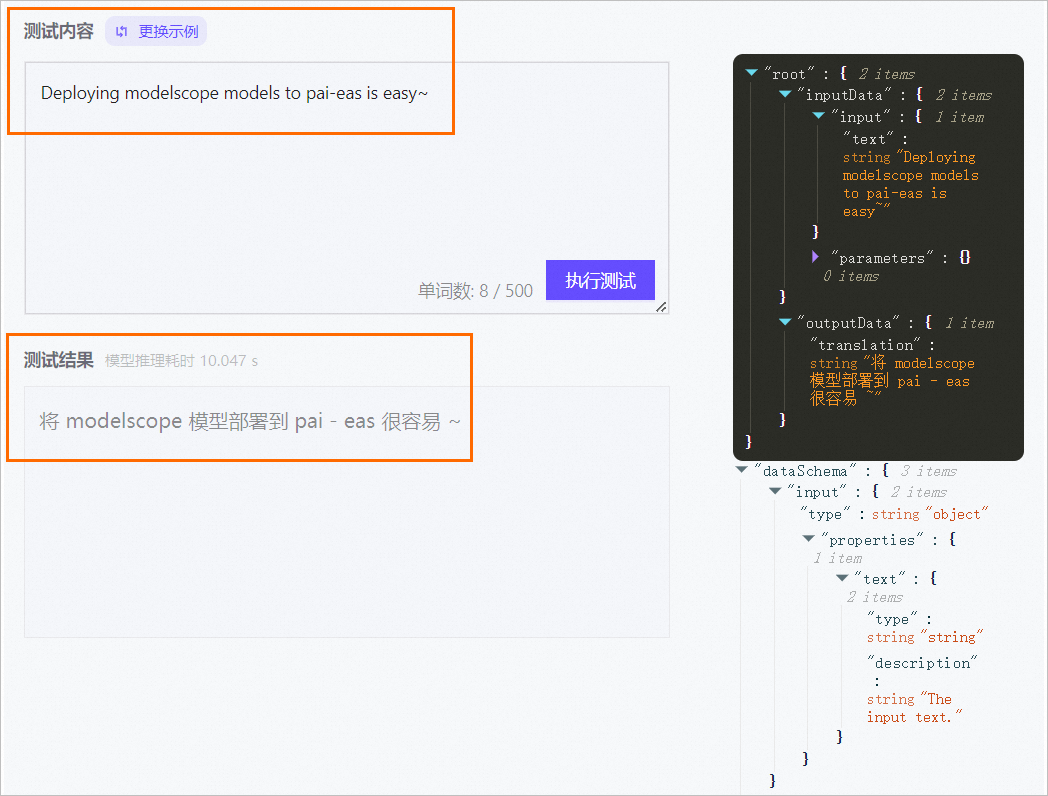
WebUI页面右侧为输入数据的Schema,如果发送了请求之后,会显示输入输出的真实数据内容。您可以根据Schema和JSON内容,构造请求数据,来调用模型服务。
通过API接口调用模型服务
为了方便演示,以在线调试为例为您说明调用方式和返回结果:
在模型在线服务(EAS)页面,单击目标服务操作列下的在线调试。如果您不清楚该模型对应的数据格式,可以直接在在线调试页面单击发送请求,获得如下图所示的请求数据格式。
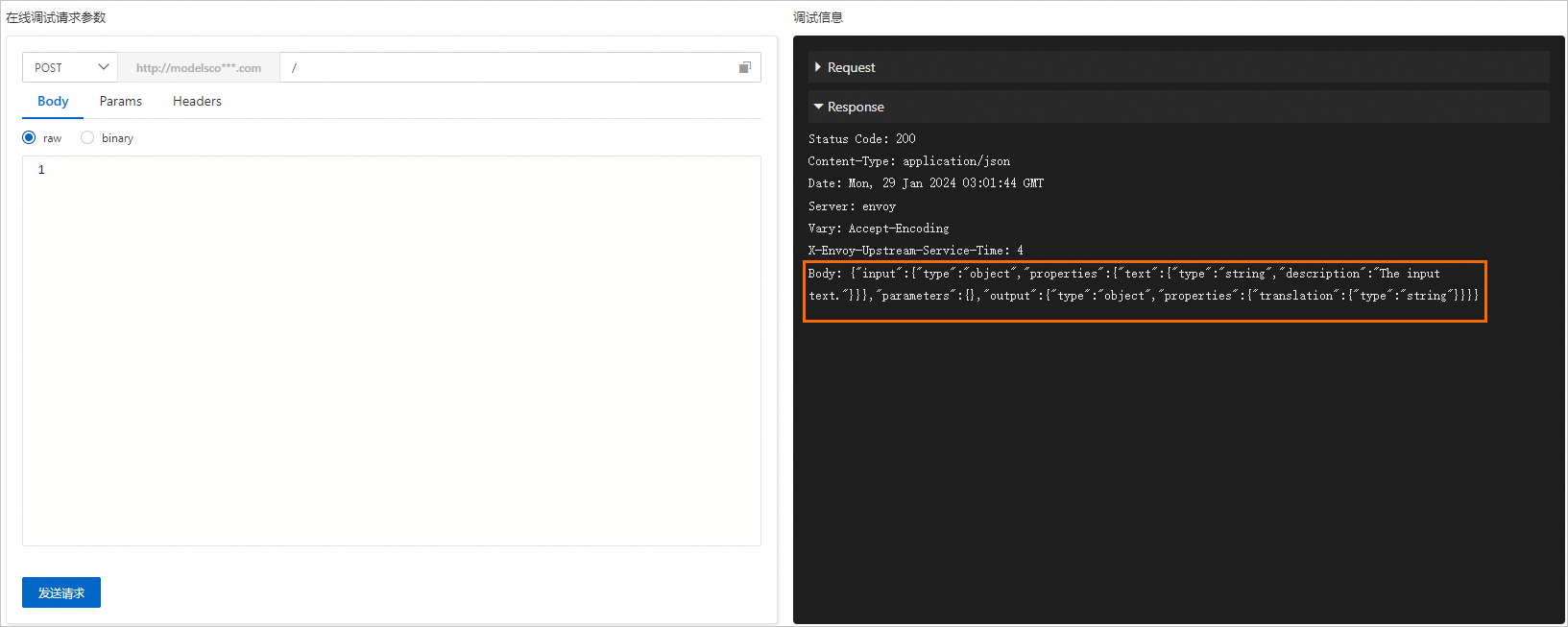
您可以参考实际返回结果中Body后的请求数据格式自行构造请求数据。以上图为例,您可以在左侧Body下的文本框中输入
{"input": {"text": "Deploying ModelScope models on PAI-EAS is simple and easy to use"}},单击发送请求,获得如下预测结果。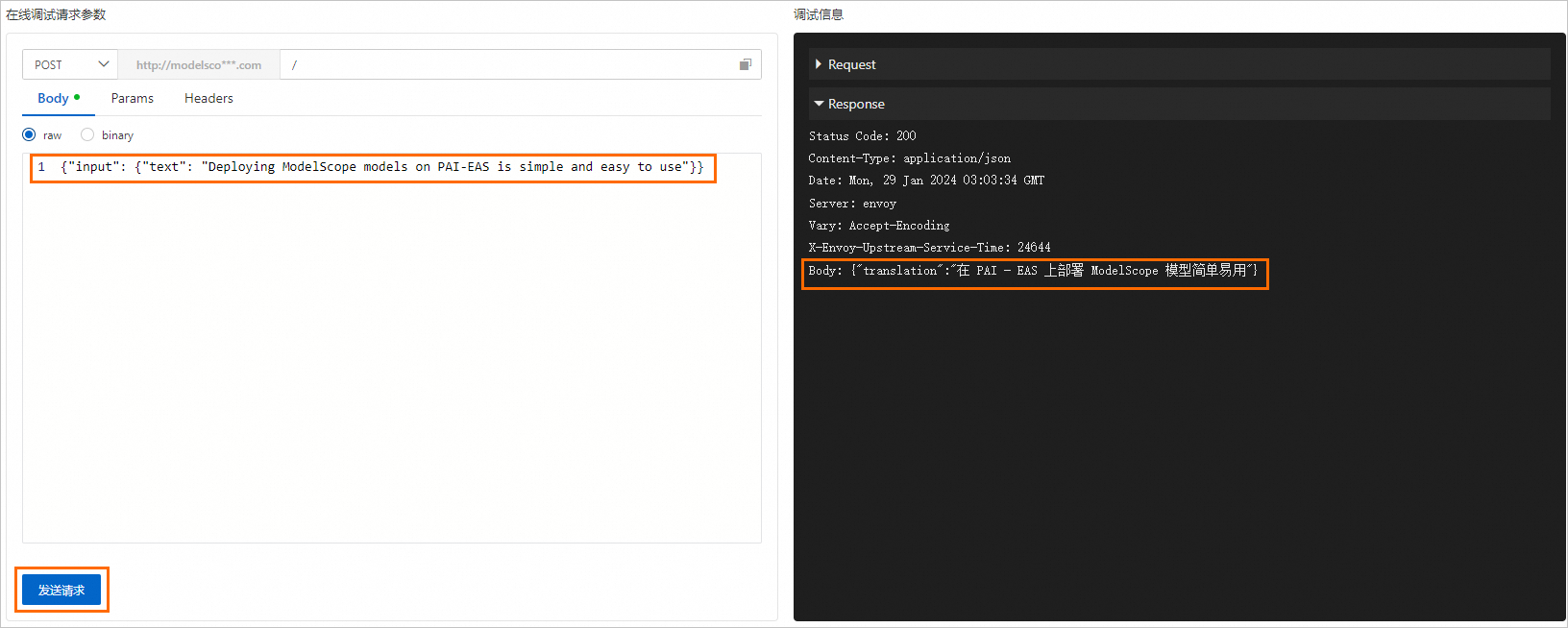
您可以使用PAI提供的SDK或curl命令发送POST请求,详情请参见服务调用SDK。您也可以自行编写代码调用模型服务,具体操作步骤如下:
获取服务的访问地址和Token。
在模型在线服务(EAS)页面,单击服务名称,进入服务详情页面。
在服务详情页面,单击基本信息区域的查看调用信息。
在公网地址调用页签,获取服务的访问地址和Token。
调用模型服务。
您可以使用PAI提供的SDK或curl命令发送POST请求,详情请参见服务调用SDK。您也可以自行编写代码调用模型服务,示例代码如下:
import requests import json service_url = 'YOUR_SERVICE_URL' token = 'YOUR_SERVICE_TOKEN' resp = requests.post(service_url, headers={"Authorization": token}, data=json.dumps({"input": {"text": "Deploying ModelScope models on PAI-EAS is simple and easy to use"}})) print(resp.text) # 输出为模型的输出结果。其中:
service_url:配置为已获取的服务访问地址。
token:配置为已获取的服务Token。
上述示例以文本模型为例,EAS同样支持语音或图像领域的模型。您可以参照上述步骤部署语音类和图像类模型,以及调用模型来验证模型效果。
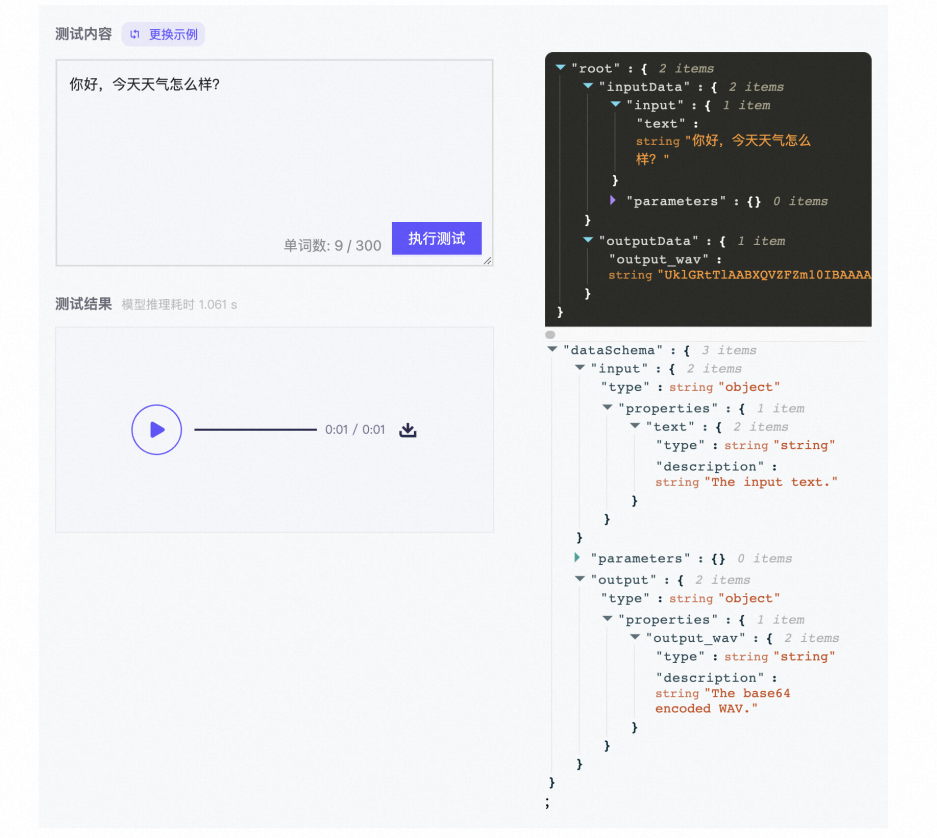
语音合成tts模型:damo/speech_sambert-hifigan_tts_zh-cn_16k。示例效果如下图所示:
图像相关的人像美肤模型:damo/cv_unet_skin-retouching。示例效果如下图所示:

对于图像类模型,输入需要传入图片的Base64编码或图片的URL地址。如果选择使用URL地址作为输入,需要确保部署的服务具有公网访问权限,详情请参见公网连接及白名单配置。
调用代码示例如下,该代码下载了一张公开的图像,将其转换为Base64编码,并将其作为请求的内容发送到已部署的服务接口,以获取模型输出的结果。
import requests import json import base64 service_url = 'YOUR_SERVICE_URL' token = 'YOUR_SERVICE_TOKEN' with requests.get('https://modelscope.oss-cn-beijing.aliyuncs.com/test/images/retina_face_detection.jpg') as img_url: img = img_url.content img_base64encoded = base64.b64encode(img) request = {"input": {"image": img_base64encoded.decode()}} request_data = json.dumps(request) resp = requests.post(service_url, headers={"Authorization": token}, data=request_data) # 传入图片URL需要服务开通公网访问权限。 # data=json.dumps({"input": {"image": 'https://modelscope.oss-cn-beijing.aliyuncs.com/test/images/retina_face_detection.jpg'}})) print(resp.text) # 输出为模型的输出结果。其中:
service_url:配置为已获取的服务访问地址。
token:配置为已获取的服务Token。
图像人脸融合模型:damo/cv_unet-image-face-fusion_damo。示例效果如下图所示:
调用大语言对话模型服务
以ChatGLM系列模型为例:
启动WebUI调用模型服务
服务部署成功后,单击服务方式列下的查看Web应用,即可打开一个类似下图页面的对话窗口,在该页面可以直接开始对话。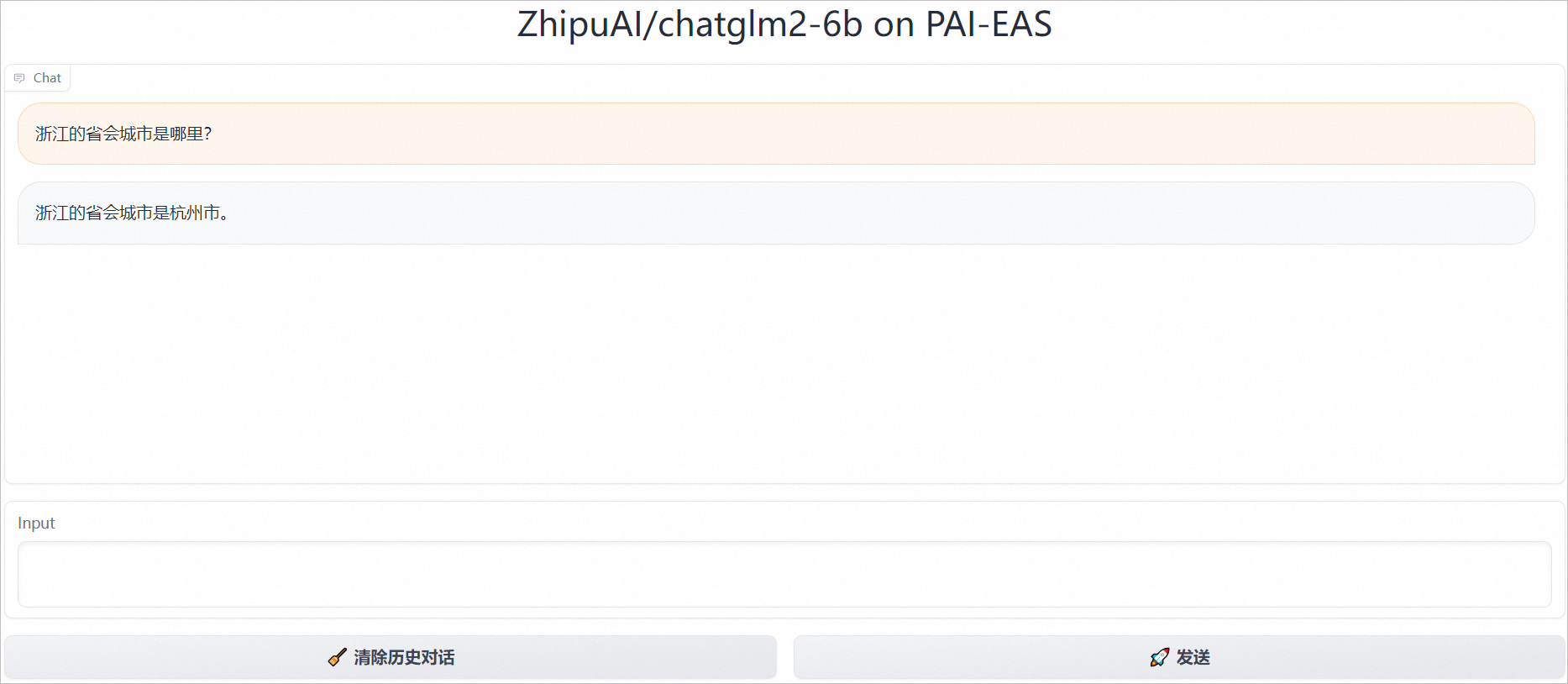
通过API接口调用模型服务
获取服务的访问地址和Token。
在模型在线服务(EAS)页面,单击服务名称,进入服务详情页面。
在服务详情页面,单击基本信息区域的查看调用信息。
在公网地址调用页签,获取服务的访问地址和Token。
调用模型服务。
您可以使用PAI提供的SDK或curl命令发送POST请求,详情请参见服务调用SDK。您也可以自行编写代码调用模型服务,示例代码如下:
import requests import json service_url = 'YOUR_SERVICE_URL' token = 'YOUR_SERVICE_TOKEN' request = {"prompt": "浙江的省会是哪里?", "history": []} resp = requests.post(service_url, headers={"Authorization": token}, data=json.dumps(request)) result = json.loads(resp.text) response = result['response'] print(json.loads(resp.text)['response']) # 浙江的省会是杭州。 request = {"prompt": "江苏呢?", "history": result['history']} resp = requests.post(service_url, headers={"Authorization": token}, data=json.dumps(request)) result = json.loads(resp.text) response = result['response'] print(response) # 江苏的省会是南京。其中:
service_url:配置为已获取的服务访问地址。
token:配置为已获取的服务Token。
request:对话模型的输入,格式为JSON。
{"prompt":"福建呢?","history":[["浙江的省会是哪里?","杭州"],["江苏呢?","南京"]]}prompt:对话模型的输入语句。
history:对话历史,格式为一个二维列表。第一维列表中每个元素为一个长度为2的列表,表示每一轮对话的问题和回答,可以直接从上次对话中获取,以实现连续对话。您也可以截取该列表的长度以限制上下文对话轮数。
输出结果为JSON格式,示例如下:
{"response":"福州","history":[["浙江的省会是哪里?","杭州"],["江苏呢?","南京"],["福建呢?","福州"]]}其中:
response:为对话模式的回答。
history:含义与request请求字段中的history描述相同,可以直接带入下一轮对话。
为了方便演示,以在线调式为例为您说明调用方式和返回结果:
在模型在线服务(EAS)页面,单击目标服务操作列下的在线调试。
在调试页面的在线调试请求参数区域的Body处填写
{"prompt":"福建呢?","history":[["浙江的省会是哪里?","杭州"],["江苏呢?","南京"]]},然后单击发送请求,即可在调式信息区域查看预测结果。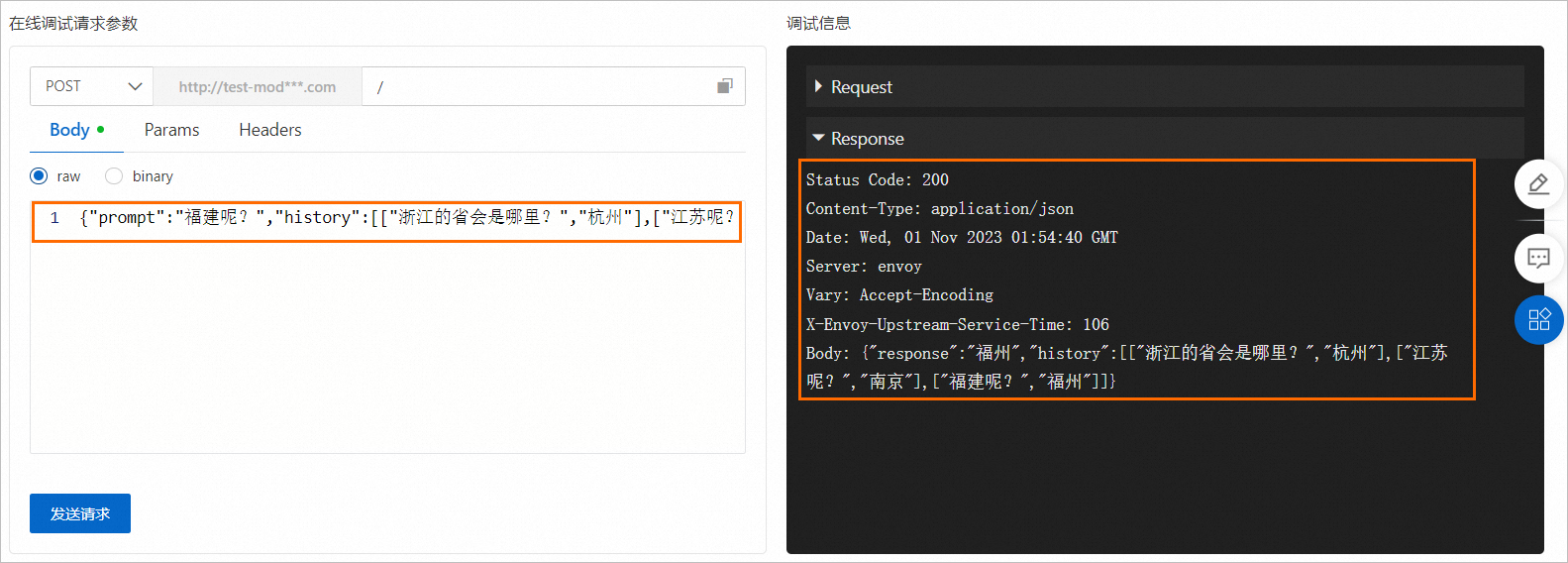
相关文档
如何基于Triton Server推理服务引擎部署EAS服务,请参见Triton Inference Server镜像部署。
您也可以开发自定义镜像,使用自定义镜像部署EAS服务。具体操作,请参见服务部署:自定义镜像。